
Impressum Frank Seitz Wassermühlenstr. 2 25436 Uetersen E-Mail: fs Tel.: +49-176-78243503 Alle Artikel Inhaltsverzeichnis Rechtliche Hinweise Code auf GitHub Code auf meta::cpan KategorienAbonnierenValidierung |
Montag, 8. Juli 2024SQLite client (sqlite3) mit Transaktionen und Foreign Key Constraints
SQLite unterstützt Transaktionen und Forein Key Constraints. Diese sind bei Nutzung des interaktiven Clients sqlite3 per Default allerdings nicht aktiviert. Eine automatische Aktivierung lässt sich durch eine geeignete Startup-Datei erreichen: $ vi ~/.sqliterc BEGIN TRANSACTION; PRAGMA foreign_keys = ON; Von nun an werden Datenänderungen per INSERT, UPDATE, DELETE auf der Datenbank erst permanent, wenn sie mit COMMIT bestätigt werden. Mit ROLLBACK können sie wahlweise verworfen werden. Sonntag, 14. November 2021SQLite-Datenbank von einem entfernten Rechner zugreifen
SQLite ist ein leichtgewichtiges relationales Datenbanksystem, das genial konzipiert, allerdings nicht netzwerkfähig ist. Letzteres ist laut der Autoren Absicht: "SQLite is designed for situations where the data and application coexist on the same machine." Mitunter möchte man dennoch eine SQLite-Datenbank von einem entfernten Rechner zugreifen. Dass es keine gute Idee ist, wie es im Netz öfter als Lösung genannt wird, die Datenbankdatei (eine SQLite-Datenbank besteht aus einer einzigen Datei) auf ein Netzwerk-Dateisystem zu legen, wird von den Autoren in SQLite Over a Network, Caveats and Considerations dargelegt. Unter Perl lässt sich der Netzwerk-Zugriff auch solide unter Rückgriff auf DBI und dessen Proxy-Server realisieren. Der Unterschied ist, dass in dem Fall die API Schicht ins Netz verlegt wird und nicht die File-I/O Schicht (s. obiges Dokument). Starten des Proxy-Servers auf dem Rechner mit der SQLite-Datenbank: $ ssh USER@HOST "bash -lc 'dbiproxy --localport=PORT'" Zugriff auf die Datenbank aus Perl heraus von einem beliebigen Rechner aus: use DBD::SQLite;
my $dbh = DBI->connect('dbi:Proxy:hostname=HOST;port=PORT;dsn=DSN',{
RaiseError => 1,
ShowErrorStatement => 1,
});
# ab hier können wir auf die SQLite-Datenbank zugreifen, als ob sie lokal wäre
Hierbei ist:
Eine breitere Darstellung der Möglichkeiten des DBI Proxy-Servers findet sich in Programming the Perl DBI - Database Proxying. Warnung: Der DBI Proxy-Server hat offenbar ein Memory Leak und sollte daher nicht unbegrenzt lange laufen. Soll lediglich mit dem SQLite-Client auf eine entfernte Datenbank zugegriffen werden, kann dies per ssh(1) erreicht werden: $ ssh -t USER@HOST sqlite3 PATH
Mittwoch, 27. Januar 2021Oracle+Linux: ORA-00845: MEMORY_TARGET not supported on this system
Unter Linux (Debian) bricht eine zuvor funktionierende Oracle-Datenbank beim Hochfahren plötzlich ab. Die Meldung lautet: ORA-00845: MEMORY_TARGET not supported on this system Im Netz wird in Blogs als Lösung genannt, man möge /dev/shm mounten # mount -t tmpfs tmpfs -o size=2g /dev/shm oder, falls /dev/shm bereits gemountet ist, den Speicher vergrößern # mount -o remount,size=2g /dev/shm Dies hat beides allerdings nicht geholfen, da es eine weitere Fehlerursache gibt. Die Meldung im alert_<DB>.log zu dem Fehler lautet: WARNING: You are trying to use the MEMORY_TARGET feature. This feature requires the /dev/shm file system to be mounted for at least 1275068416 bytes. /dev/shm is either not mounted or is mounted with available space less than this size. Please fix this so that MEMORY_TARGET can work as expected. Current available is 0 and used is 0 bytes. Ensure that the mount point is /dev/shm for this directory. Der entscheidende Punkt in der Meldung, welcher zur Lösung führt, ist, dass Oracle keinen verfügbaren Speicher erkennt ("Current available is 0 and used is 0 bytes") und dass der Mountpoint exakt /dev/shm sein muss ("Ensure that the mount point is /dev/shm for this directory"). Letztere Bedingung war auf dem Debian-System (testing) nicht erfüllt: # df -h /dev/shm Filesystem Size Used Avail Use% Mounted on tmpfs 3.0G 0 3.0G 0% /run/shm Als Mountpoint wird hier nicht /dev/shm angezeigt, sondern /run/shm, weil /dev/shm lediglich ein Symlink auf /run/shm ist: # ls -l /dev/shm lrwxrwxrwx 1 root root 8 Aug 7 09:37 /dev/shm -> /run/shm Mit diesem Setup kommt der Oracle-Kernel (11.2.0.1.0) nicht klar. Er erkennt (aus nicht weiter erforschten Gründen) die Größe des Shared-Memory-Bereichs nicht. Der Fix besteht darin, im Oracle-Kernel alle Vorkommen von /dev/shm durch /run/shm zu ersetzen: # cd $ORACLE_HOME/bin # cp oracle oracle.bak # sed 's|/dev/shm|/run/shm|g' oracle.bak >oracle Danach fährt die Datenbank wieder hoch: $ sqlplus / as sysdba SQL*Plus: Release 11.2.0.1.0 Production on Fri Aug 7 13:29:21 2020 Copyright (c) 1982, 2009, Oracle. All rights reserved. Connected to an idle instance. SQL> startup ORACLE instance started. Total System Global Area 1272213504 bytes Fixed Size 1336260 bytes Variable Size 805309500 bytes Database Buffers 452984832 bytes Redo Buffers 12582912 bytes Database mounted. Database opened. LinksMittwoch, 21. Oktober 2020MS SQL Server: DB-übergreifender Zugriff auf Tabelle nur über View
Ausgangslage:
Anforderung: Es soll ein Server-Zugang mylogin geschaffen werden, der Daten über View myschema2.myview selektieren darf, aber nicht direkt aus Tabelle myschema1.mytable. Lösung:
SQL: CREATE LOGIN mylogin WITH PASSWORD = 'mypassword';
CREATE DATABASE mydb1;
ALTER DATABASE mydb1 SET DB_CHAINING ON;
CREATE DATABASE mydb2;
ALTER DATABASE mydb2 SET DB_CHAINING ON;
USE mydb1;
CREATE SCHEMA myschema1;
CREATE TABLE myschema1.mytable (id INT PRIMARY KEY);
CREATE USER myuser1 FOR LOGIN mylogin;
USE mydb2;
CREATE SCHEMA myschema2;
CREATE USER myuser2 FOR LOGIN mylogin;
CREATE VIEW myschema2.myview AS SELECT * FROM mydb1.myschema1.mytable;
GRANT SELECT ON myschema2.myview TO myuser2;
Über mylogin ausgeführt: -- erfolgreich
SELECT * FROM mydb2.myschema2.myview;
-- schlägt fehl: The SELECT permission was denied on the object 'mytable',
-- database 'mydb1', schema 'myschema1'
SELECT * FROM mydb1.myschema1.mytable;
Freitag, 9. Oktober 2020SQL: SELECT-Statement in einer Methode kapseln
Das potentiell komplexeste Statement in SQL ist das SELECT-Statement. Dieses wiederverwendbar zu kapseln, z.B. in einer Methode einer Klasse, kann eine Herausforderung sein. Dieses Problem wollen wir hier allgemeingültig lösen. Hier ein Beispiel. Mit folgendem SELECT-Statement wollen wir aus dem Data Dictionary (Catalog) von PostgreSQL Informationen über die auf der Datenbank definierten Datenbank-Funktionen abfragen: SELECT
fnc.oid AS fnc_oid
, usr.usename AS fnc_owner
, nsp.nspname AS fnc_schema
, fnc.proname AS fnc_name
, pg_get_function_identity_arguments(pro.oid) AS fnc_arguments
, pg_get_functiondef(fnc.oid) AS fnc_source
FROM
pg_proc AS fnc
JOIN pg_namespace AS nsp
ON fnc.pronamespace = nsp.oid
JOIN pg_user usr
ON fnc.proowner = usr.usesysid
Dieses relativ kurze Statement besitzt eine beachtliche Komplexität. Es erstreckt sich über drei Relationen (zwei Tabellen, eine View), deren Aufbau und Verknüpfung alles andere als offensichtlich ist. Wir wollen es so kapseln, dass wir bei Abfragen keine Details über die interne Repräsentation des Data Dictionary wissen müssen. In einem ersten Schritt haben wir den Kolumnen bereits Aliasnamen gegeben (s.o.), aus denen sich die Bedeutung der Kolumnen recht klar ergibt:
Über diesen Kolumnen wollen wir unsere Abfragen formulieren. Das Problem ist jedoch, dass wir die Kolumnen-Aliase nicht überall in einer Abfrage verwenden können, auch nicht in der WHERE-Klausel, die die Ergebnismenge bestimmt. Wenn wir obiges Statement um eine WHERE-Klausel ergänzen, müssen wir dort also weiterhin die internen Namen verwenden. Das wollen wir gerade nicht. Eine mögliche Lösung ist das Anlegen einer View: CREATE VIEW function_view AS
<obiges_statement>
Durch die View werden die internen Namen verdeckt. Abfragen der View werden allein über den Kolumnennamen des zugrundeliegenden Statements formuliert. Das ist genau das, was wir wollen. Mit der View schaffen wir allerdings eine öffentliche Schnittstelle, die wir (ohne besondere Vorkehrungen) nicht nach Belieben anlegen (Namenskonflikte) und ändern können (wir wissen nicht, wer die View sonst noch nutzt). Dies ist das Gegenteil einer Kapselung. Das Ziel einer echten Kapselung in einer Methode, und nur dort, erreichen wir mit einer View nicht. Eine in dieser Hinsicht bessere Lösung bietet eine Inline-View, die nur innerhalb unserer Methode bekannt ist. Bei einer Inline-View betten wir das Select-Statement in die FROM-Klausel unserer Abfrage ein: SELECT
...
FROM (
<obiges_statement>
) AS function_view
...
Diese Lösung hat jedoch den Nachteil, dass sie nicht portabel ist. Z.B. erzwingt PostgreSQL einen Namen für die Inline-View (AS function_view), Oracle jedoch nicht. Wobei ein Name im Falle von Oracle zwar vereinbart werden kann, dann aber ohne das Schlüsselwort AS. Eine weitere Möglichkeit bietet die Einbettung in eine WITH-Klausel: WITH function_view AS (
<obiges_statement>
)
SELECT
...
FROM
function_view
...
Diese Lösung ist portabel und separiert die konkrete Abfrage (SELECT ... FROM function_view ...) klar von dem gekapselten SELECT-Statement. Auf dieser Grundlage können wir die Selektion wie gewünscht kapseln. Hier die Implementierung einer Methode in Perl, die so ausgelegt ist, dass die Klauseln SELECT (Namensparameter select), WHERE (Namensparameter where) und ORDER BY (Namensparameter orderBy) frei gesetzt werden können: package PostgreSql::Catalog;
sub functionSelect {
my ($class,%clause) = @_;
# Defaults
$clause{'select'} //= ['*']; # Default für SELECT-Klausel
$clause{'from'} = ['function_view']; # FROM-Klausel ist festgelegt
# Gekapselter Statement-Rumpf
my $stmt = << ' __SQL__';
WITH function_view AS (
SELECT
fnc.oid AS fnc_oid
, usr.usename AS fnc_owner
, nsp.nspname AS fnc_schema
, fnc.proname AS fnc_name
, pg_get_function_identity_arguments(pro.oid) AS fnc_arguments
, pg_get_functiondef(fnc.oid) AS fnc_source
FROM
pg_proc AS fnc
JOIN pg_namespace AS nsp
ON fnc.pronamespace = nsp.oid
JOIN pg_user usr
ON fnc.proowner = usr.usesysid
)
__SQL__
$stmt =~ s/^ //mg;
# Erzeuge vollständiges Statement über den angegebenen Klauseln
for my $key (qw/select from where orderBy/) {
if (my $arr = $clause{$key}) {
my $clause = $key eq 'orderBy'? 'ORDER BY': uc $key;
$stmt .= sprintf "%s\n %s\n",$clause,join "\n , ",@$arr;
}
}
return $stmt;
}
Beispiel: Der Aufruf # Ermittele alle Funktionen im Schema 'donald', deren Quelltext
# die Zeichenkette 'to_date' enthält
$sql = PostgreSql::Catalog->functionSelect(
select => [
"fnc_schema",
"fnc_name || '(' || fnc_arguments || ')' AS fnc_signature",
],
where => [
"fnc_schema = 'donald'",
"fnc_source LIKE '%to_date%'",
],
orderBy => [
1,
2
],
);
generiert das Statement WITH function_view AS (
SELECT
fnc.oid AS fnc_oid
, usr.usename AS fnc_owner
, nsp.nspname AS fnc_schema
, fnc.proname AS fnc_name
, pg_get_function_identity_arguments(pro.oid) AS fnc_arguments
, pg_get_functiondef(fnc.oid) AS fnc_source
FROM
pg_proc AS fnc
JOIN pg_namespace AS nsp
ON fnc.pronamespace = nsp.oid
JOIN pg_user usr
ON fnc.proowner = usr.usesysid
)
SELECT
fnc_schema
, fnc_name || '(' || fnc_arguments || ')' AS fnc_signature
FROM
function_view
WHERE
fnc_schema = 'donald'
AND fnc_source LIKE '%to_date%'
ORDER BY
1
, 2
das wir gegen die Datenbank ausführen können. Wir haben folgendes erreicht:
Donnerstag, 25. Februar 2016MySQL: Join mit mehrwertiger Fremdschlüsselkolumne durch find_in_set()
Der reinen Datenbank-Lehre nach ist es strikt verboten mehrere Werte auf einem Attribut zu speichern. Sowas kommt in der Realität trotzdem vor, sogar bei Fremdschlüssel-Attributen. D.h. das Fremdschlüssel-Attribut referenziert in dem Fall nicht nur eine, sondern mehrere Zeilen. Die gute Nachricht ist, dass MySQL es erlaubt, für so ein - ansich unterlaubtes - Design mithilfe der Funktion find_in_set() eine Join-Condition zu formulieren. BeispielGegeben zwei Tabellen TableA und TableB, wobei Attribut TableB.tablea_id auf mehrere Zeilen in TableA verweist. TableA TableB id id tablea_id -- -- --------- 1 1 2,3 2 2 3 3 3 1,2,3,4 4 4 NULL Wäre TableB.tablea_id ein normales Fremdschlüssel-Attribut mit einem Wert sähe die Join-Condition so aus: TableA.id = TableB.tablea_id Diese Bedingung ist hier nicht anwendbar, da eine Identität (=) zwischen TableA.id und TableB.tablea_id nur manchmal gegeben ist. Die Selektion SELECT
b.id b_id
, a.id a_id
FROM
TableA a
INNER JOIN TableB b
ON a.id = b.tablea_id
ORDER BY
b.id
, a.id
liefert ein falsches Resultat +------+------+ b_id | a_id | +------+------+ | 1 | 2 | zweifelhaft | 2 | 3 | erwartet | 3 | 1 | zweifelhaft +------+------+ Da MySQL bei numerischen Identitäts-Vergleichen eine laxe Auffassung hat und gegen den numerischen Anfang einer Zeichenkette vergleicht, auch wenn die Zeichenkette insgesamt keine Zahl darstellt, ist die Ergebnismenge zusätzlich zweifelhaft. Statt der erwarten einen Zeile werden drei Zeilen geliefert. MySQL besitzt jedoch eine Funktion find_in_set(), mit deren Hilfe eine Join-Condition formuliert werden kann, die die mehrwertigen Verweise korrekt auflöst: FIND_IN_SET(TableA.id, TableB.tablea_id) > 0 Die Selektion SELECT
b.id b_id
, a.id a_id
FROM
TableA a
INNER JOIN TableB b
ON FIND_IN_SET(a.id, b.tablea_id) > 0
ORDER BY
b.id
, a.id
liefert das korrekte Resultat +------+------+ b_id | a_id | +------+------+ | 1 | 2 | | 1 | 3 | | 2 | 3 | | 3 | 1 | | 3 | 2 | | 3 | 3 | | 3 | 4 | +------+------+ LinksMittwoch, 10. Juni 2015PostgreSQL: Installation und Konfiguration
PostgreSQL gilt als das beste frei erhältliche Relationale Datenbanksystem. Es besitzt viele Gemeinsamkeiten mit Oracle, ist aber wesentlich leichter zu administrieren. Hier die wichtigsten Kommandos, um damit an den Start gehen zu können. PostgreSQL RDBMS installieren (Debian)# apt-get install postgresql Zum DB-Admin machen# su - postgres Nur von diesem Unix-Account aus kann nach der Installation eine Connection zum DBMS aufgebaut werden. Liste der existierenden Datenbanken$ psql -l [Liste] Nach der Installation existiert zunächst nur die Datenbank postgres. Datenbank erzeugen/zerstören$ createdb DB ... $ dropdb DB Liste der existierenden Benutzer$ psql postgres=# \du oder postgres=# SELECT rolname FROM pg_roles; Benutzer anlegen/entfernen$ createuser USER ... $ dropuser USER Bei Angabe der Option --superuser erhält der Benutzer Admin-Rechte: $ createuser --superuser USER Benutzer sind global für alle Datenbanken einer Installation. Zunächst existiert nur der Benutzer postgres. Soll der User USER von einem anderen Account als dem entsprechenden Unix-Account connecten können, muss ein Passwort vergeben werden. Option -P. DatenbankzugriffIst ein DB-User erzeugt, kann dieser vom gleichnamigen Unix-Account oder per Passwort, falls eins vergeben wurde, von einem anderen Account per psql auf die Datenbank zugreifen. USER$ psql DB psql (9.4.3) Type "help" for help. ... DB=# Wurde ein Passwort für User USER vergeben, aber die Anmeldung von einem anderen Accout aus schlägt fehl mit der Meldung $ psql -U USER DB psql: FATAL: Peer authentication failed for user "USER" dann muss in pg_hba.conf die Authentisierungsmethode für lokale Logins geändert werden von local all all peer in local all all md5 und anschließend der Server neu gestartet werden. Liste der existierenden Objekte
Liste aller interaktiven psql-Kommandos: \? Exportieren/Importieren
Session-EinstellungenZeitzoneDie Zeitzone kann für eine Session abweichend gesetzt werden: SET TIME ZONE 'Europe/Berlin'; Die Default-Zeitzone ist in postgresql.conf definiert: timezone = 'Europe/Berlin' DatumsformatDatumsangaben im Format YYYY-MM-DD: SET datestyle TO iso, ymd; Aktueller Zeitpunkt: select localtimestamp(0); liefert die Zeit entsprechend dem eingestellten Format 2015-06-09 11:44:29 ZeichensatzClient arbeitet mit ISO-8859-1: SET client_encoding TO iso88591 Client arbeitet mit UTF-8: SET client_encoding TO utf8 Siehe: http://www.postgresql.org/docs/9.4/static/multibyte.html Der clientseitige Zeichensatz kann jederzeit umgeschaltet werden. Wenn Daten mit unterschiedlichem Encoding verarbeitet werden, besteht die Möglichkeit, vor dem Schreiben auf die Datenbank das clientseitige Encoding umzuschalten. Die Konvertierung wird dann vom Server übernommen. \-Escapes in Stringliteralen verbietenSET standard_conforming_strings TO on Server-Zugriff von externen HostsDie folgenden Einträge ermöglichen den Zugriff von allen Hosts für alle User und alle Datenbanken.
Server neu starten# /etc/init.d/postgresql-X.Y restart Upgrade auf eine neue VersionSiehe Kapitel "Upgrading" in der Doku. LinksMittwoch, 10. April 2013SSH: Über SSH-Tunnel mit MySQL Datenbank verbinden
Eine MySQL-Datenbank, die von innen (Host oder lokalem Netzwerk), jedoch nicht von außen (Internet) per TCP/IP erreichbar ist, kann von einem entfernten Rechner über einen SSH-Tunnel erreicht werden, wenn man einen SSH-Zugang zu dem Datenbank-Host oder einem Host des Netzwerks besitzt. 1 - SSH-Tunnel zum MySQL Port 3306 aufsetzen: $ ssh <user>@<host> -L <port>:localhost:3306 -f -N -L <port>:localhost:3306 : Verbinde lokalen Port <port> remote mit MySQL Port 3306 -f : Lege den ssh-Prozess in den Hintergrund -N : Führe remote nichts aus (kein Login, kein Kommando) 2 - Mit der Datenbank verbinden: $ mysql --host=localhost --port=<port> --protocol=tcp ... oder $ mysql --host=127.0.0.1 --port=<port> ... Dieser spezielle Fall von SSH-Tunneling kann natürlich auch auf andere Dienste (Ports) übertragen werden. Ein weiterer Artikel zu dem Thema: http://www.revsys.com/writings/quicktips/ssh-tunnel.html phpMyAdminUm mit einer lokalen phpMyAdmin-Applikation über den Tunnel auf die Remote-Datenbank zugreifen zu können, wird eine entsprechende Server-Definition in der phpMyAdmin-Konfiguration vereinbart, z.B. in /etc/phpmyadmin/conf.d/<Server-Name>.php: <?php $cfg['Servers'][$i]['verbose'] = '<Server-Name>'; $cfg['Servers'][$i]['host'] = '127.0.0.1'; $cfg['Servers'][$i]['port'] = '3305'; $cfg['Servers'][$i]['connect_type'] = 'tcp'; $i++; Das Timeout hochsetzen: $cfg['LoginCookieValidity'] = <Wert in Sekunden>; Z.B. ein Tag: $cfg['LoginCookieValidity'] = 86400; 0 bedeutet nicht unendlich, sondern sofortiges Logout! Freitag, 23. März 2012Lookup-Trigger für Oracle und PostgreSQL
Gegeben ist eine Tabelle <table> mit einer Kolumne <x>, deren Wert frei manipuliert werden kann, und einer Kolumne <y>, deren Wert funktional von <x> abhängt (also nicht frei manipuliert werden kann). Die Abbildung von <x> auf <y> ist in einer Lookup-Tabelle <lookup_table> definiert, die jedem Wert <x> den entsprechenden Wert <y> zuordnet. Aufgabe: Der <y>-Wert soll in <table> gespeichert werden und stets konstitent zu <x> sein. Der Wert von <y> soll nicht erst bei Abfrage ermittelt werden. Im Prinzip ist das eine unerwüschte Redundanz, die aber aus praktischen Gründen sinnvoll sein kann. Die Anforderung lässt sich durch einen BEFORE INSERT OR UPDATE-Trigger erfüllen, der beim Einfügen oder Ändern in <table> den <y>-Wert via <x> in <lookup_table> ermittelt und auf <table>.<y> überträgt. Es folgt die Lösung für Oracle und PostgreSQL. Oracle1 CREATE OR REPLACE TRIGGER <tigger> BEFORE INSERT OR UPDATE 2 ON <table> FOR EACH ROW 3 BEGIN 4 SELECT 5 <y> 6 INTO 7 :new.<y> 8 FROM 9 <lookup_table> 10 WHERE 11 <x> = :new.<x>; 12 END; PostgreSQL1 CREATE FUNCTION <trigger_func>() RETURNS trigger AS $$ 2 BEGIN 3 SELECT 4 <y> 5 INTO STRICT 6 NEW.<y> 7 FROM 8 <lookup_table> 9 WHERE 10 <x> = NEW.<x>; 11 12 RETURN NEW; 13 END; 14 $$ LANGUAGE plpgsql; 15 16 CREATE TRIGGER <trigger> BEFORE INSERT OR UPDATE 17 ON <table> FOR EACH ROW 18 EXECUTE PROCEDURE <trigger_func>(); Der Code ist bei beiden Datenbanksystemen ähnlich, die Unterschiede sind im Wesentlichen:
Dienstag, 28. Februar 2012PostgreSQL: Notizen zum psql Kommando-Interpreter
Startup-Datei anlegen/ändern: $ vi ~/.psqlrc Die Kommandos in der Datei führt der Interpreter beim Start aus. Hier können persönliche Einstellungen vorgenommen werden. Z.B. kann man dort den Pager aus- und die Zeitmessung einschalten. Pager abschalten: <db>=# \pset pager off Pager usage is off. Zeitmessung einschalten: <db>=# \timing on Timing is on. Nützliche interaktive Kommandos: Liste der Schemata: <db>=# \dn ... Liste der Tabellen eines Schemas: <db>=# \dt <schema>.* ... Tabelle, View oder Sequenz beschreiben: <db>=# \d <object> ... Spezielle SQL-Anweisungen: Liste der Runtime-Parameter: <db>=# show all; ... Montag, 5. September 2011SQL: Dubletten finden
SELECT col1, ..., colN, COUNT(*) FROM tab GROUP BY col1, ..., colN HAVING COUNT(*) > 1 col1, ..., colN sind die Kolumnen, über denen die Dubletten-Eigenschaft geprüft wird. Dienstag, 30. August 2011MySQL: Data Directory neu aufsetzen
Montag, 29. August 2011MySQL: Mehrere Instanzen auf einem Server
Eine elegante Möglichkeit, mehrere MySQL-Instanzen auf einem Server zu betreiben, bietet das Programm mysqld_multi. Es erweitert die Konfigurationsdatei /etc/my.cnf um Abschnitte für mehrere MySQL-Serverinstanzen [mysqld#] (wobei # die jeweilige Instanznummer bezeichnet). In den Abschnitten werden den Instanzen getrennte Datadirs, Sockets, Ports, Pid-Files usw. zugewiesen. mysqld_multi ist das Frontend-Programm zum Starten und Stoppen der einzelnen Instanzen, à la $ mysqld_multi start 2 Eine Beispielkonfiguration, die auf die eigenen Verhältnissse angepasst und in my.cnf eingesetzt werden kann, liefert das Kommando $ mysqld_multi --example Die ausführliche Doku ist auf der Manpage zu finden: $ man mysql_multi Donnerstag, 10. März 2011Oracle 11g unter Linux installieren
Eine Anleitung zum Installieren von Oracle 11g unter Debian, die versucht, mögliche Probleme von vornherein auszuschließen, dafür aber umfangreiche Vorarbeiten verlangt, findet sich hier: http://edin.no-ip.com/blog/hswong3i/oracle-database-11g-release-1-debian-sid-howto Meine Anleitung hat das Ziel, die Voraussetzungen für den Aufruf des Installers zu schaffen. Da der Installer selbst den Softwarestand und die Kernelparameter prüft, können Anpassungen auch bei laufender Installation vogenommen werden.
Schritt 1: DownloadDateien von Oracle.com herunterladen: Download 11g Enterprise Edition (Hierfür ist ein OTN-Konto nötig) Schritt 2: Oracle-Benutzer und DBA-Gruppe erzeugen# addgroup --system dba # adduser --system --home /opt/oracle --shell /bin/bash --ingroup dba --gecos 'Oracle DBA' oracle # passwd oracle Schritt 3: Dateien entpackenAuf Benutzer oracle wechseln, unter dessen Rechten wird die weitere Installation durchgeführt: # su - oracle $ unzip linux_11gR2_database_1of2.zip $ unzip linux_11gR2_database_2of2.zip Die Dateien werden von unzip in ein Unterverzeichnis database entpackt. Wo entpackt wird, ist egal. Die entpackten Dateien werden nur während der Installation gebraucht. Nach der Installtion kann das gesamte Verzeichnis gelöscht werden. Schritt 4: Installer ausführenWichtig: Wurde der Desktop unter einem anderen Benutzer als oracle gestartet, muss der Benutzer den Desktop für den Zugriff des Benutzers oracle freigeben, da dieser den Installer aufruft. Geschieht die Freigabe nicht, stirbt der Installer nach einigen Sekunden mit der wenig aussagekräftigen Fehlermeldung No protocol specified [Java Stacktrace] Die Freigabe erfolgt mit dem Kommando: <user>$ xhost + Als Benutzer oracle ausführen: $ cd database $ ./runInstaller Der Installer führt den Benutzer durch die Installation, nimmt zahlreiche Prüfungen vor und schreibt ein Logfile, das bei Problemen konsultiert werden kann. Unstimmigkeiten können parallel behoben werden, Prüfungen und fehlgeschlagene Schritte können immer wieder neu durchgeführt werden bis es klappt.
Installierte DateienKonfigurationsdateien in /etc/etc/oraInst.loc /etc/oratab Die eigentliche Installation/opt/oracle/app/* Hilfsprogramme/usr/local/bin/oraenv /usr/local/bin/coraenv /usr/local/bin/dbhome Datenbank-Dateien/var/opt/oracle/<DATABASE>/* Donnerstag, 4. November 2010MySQL: Bessere Antwortzeiten durch bessere Query-Pläne
Der MySQL Query Optimizer kann bessere Query-Pläne generieren, wenn er Informationen über die Tabelleninhalte hat. Diese können per SQL mit ANALYZE TABLE erzeugt werden oder - einfacher - mit dem Kommandozeilenprogramm mysqlcheck. Die Option zum Analysieren heißt --analyze. Bei Angabe der Option --all-databases werden alle Tabellen aller Schemata (in MySQL-Sprechweise: Datenbanken) auf einen Schlag analysiert. Das ist meistens das, was man will. $ mysqlcheck --analyze --all-databases ... bzw. in Kurzform $ mysqlcheck -a -A ... Mittwoch, 3. November 2010MySQL: Remote-Zugriff einrichten
Damit der MySQL-Server mysqld TCP-Verbindungen annimmt, muss ihm in my.cnf im Abschnitt [mysqld] eine Bind-Adresse zugewiesen werden: bind-address = <server-ip> Falls vorhanden, muss die Direktive skip-networking gleichzeitig auskommentiert werden, da diese Priorität hat und forciert, dass der Server nur Unix Domain Sockets zulässt. Per SQL einen neuen User anlegen und ihm den Remote-Zugriff von allen Hosts ('%') auf alle Schemata und Tabellen (*.*) erlauben: CREATE USER <user> IDENTIFIED BY '<password>'; GRANT ALL ON *.* TO '<user>'@'%'; Login mit mysql-Client: $ mysql -u <user> -h <host> --password=<password> Die User-Zugriffsberechtigungen stehen in der Tabelle mysql.user. Diese Tabelle kann mit INSERT/UPDATE/DELETE Statements auch direkt manipuliert werden. Mittwoch, 27. Oktober 2010ROWNUM unter MySQL
Oracle kennt die Pseudo-Kolumne ROWNUM, die die Datensätze einer Selektion von 1 an aufsteigend durchnummeriert. In MySQL existiert dieses Konzept nicht, es kann aber mittels einer Benutzer-definierten Variable simuliert werden. Implementierung:
Einschränkung: Die Lösung ist unzureichend, wenn ein ORDER BY verwendet wird, da die Nummerierung vor der Sortierung stattfindet. Unter Oracle wird ROWNUM auch benutzt, um die Ergebnismenge auf die ersten n Datensätze zu begrenzen. Dafür hat MySQL ein besseres Konzept, die SELECT-Klausel LIMIT. Freitag, 22. Januar 2010PostgreSQL: TIMESTAMP nach EPOCH wandeln und zurück
TIMESTAMP WITHOUT TIME ZONE nach EPOCHUmwandlung eines TIMESTAMP WITHOUT TIME ZONE in Unix-Epoch (Sekunden seit 1.1.1970 0 Uhr) in einer Anwendung, die mit UTC-Zeiten arbeitet: sql> SELECT EXTRACT(EPOCH FROM TIMESTAMP
'1970-01-01 00:00:00' AT TIME ZONE 'UTC') AS t;
t
---
0
Entscheidend ist hier der Zusatz "AT TIME ZONE 'UTC'", denn ein TIMESTAMP WITHOUT TIME ZONE wird als Zeit der lokalen Zeitzone interpretiert - nicht etwa UTC! Ohne den Zusatz ist das Resultat um dem Offset der lokalen Zeitzone verschoben - böse Falle. Hier das Ergebnis im Falle von MEZ (+0100): sql> SELECT EXTRACT(EPOCH FROM TIMESTAMP '1970-01-01 00:00:00') AS t; t ------- -3600 Erläuterungen
EPOCH nach TIMESTAMP WITHOUT TIMEZONEUmwandlung von Epoch-Sekunden in einen TIMESTAMP WITHOUT TIMEZONE (die 0 steht für den Epoch-Wert): sql> gkss=# SELECT TIMESTAMP 'epoch' + 0 * INTERVAL '1 second' AS t;
t
---------------------
1970-01-01 00:00:00
Erläuterungen
|
Kalender
StatistikLetzter Artikel:
13.07.2025 17:56 160 Artikel insgesamt
Links |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||




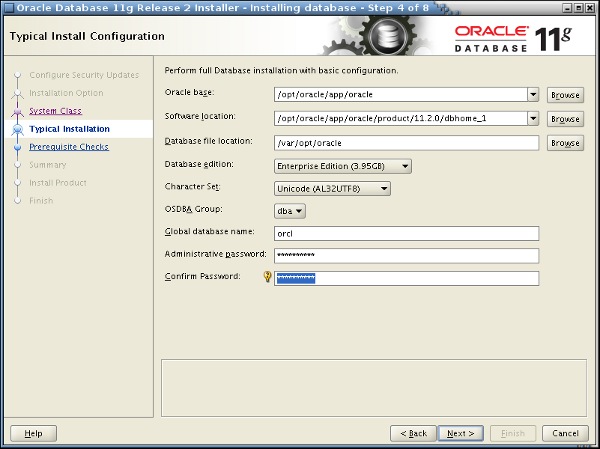 Abbildung 1: Allgemeine Konfigurationsangaben im Installer
Abbildung 1: Allgemeine Konfigurationsangaben im Installer
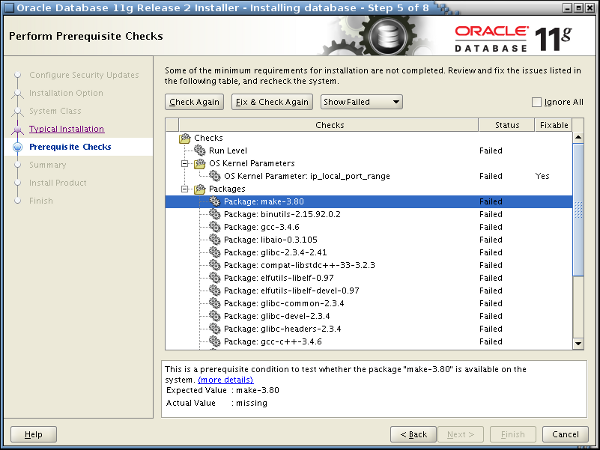 Abbildung 2: Kernel- und Software-Prüfungen durch den Installer
Abbildung 2: Kernel- und Software-Prüfungen durch den Installer